Data-Informed Thinking + Doing
Random Forest and Extra Trees for Majority Vote Predictions
Ensemble methods on decision trees for classification tasks—using R, Python, and Julia.
Data Understanding
str(cardmembers_r)'data.frame': 30000 obs. of 25 variables:
$ id : int 1 2 3 4 5 6 7 8 9 10 ...
$ limit_bal : num 20000 120000 90000 50000 50000 50000 500000 100000 140000 20000 ...
$ sex : Factor w/ 2 levels "Male","Female": 2 2 2 2 1 1 1 2 2 1 ...
$ education : Factor w/ 7 levels "0","1","2","3",..: 3 3 3 3 3 2 2 3 4 4 ...
$ marital_status : Factor w/ 4 levels "Unknown","Married",..: 2 3 3 2 2 3 3 3 2 3 ...
$ age : int 24 26 34 37 57 37 29 23 28 35 ...
$ months_payment_delayed_for_200509: int 2 -1 0 0 -1 0 0 0 0 -2 ...
$ months_payment_delayed_for_200508: int 2 2 0 0 0 0 0 -1 0 -2 ...
$ months_payment_delayed_for_200507: int -1 0 0 0 -1 0 0 -1 2 -2 ...
$ months_payment_delayed_for_200506: int -1 0 0 0 0 0 0 0 0 -2 ...
$ months_payment_delayed_for_200505: int -2 0 0 0 0 0 0 0 0 -1 ...
$ months_payment_delayed_for_200504: int -2 2 0 0 0 0 0 -1 0 -1 ...
$ bill_amt1 : num 3913 2682 29239 46990 8617 ...
$ bill_amt2 : num 3102 1725 14027 48233 5670 ...
$ bill_amt3 : num 689 2682 13559 49291 35835 ...
$ bill_amt4 : num 0 3272 14331 28314 20940 ...
$ bill_amt5 : num 0 3455 14948 28959 19146 ...
$ bill_amt6 : num 0 3261 15549 29547 19131 ...
$ pay_amt1 : num 0 0 1518 2000 2000 ...
$ pay_amt2 : num 689 1000 1500 2019 36681 ...
$ pay_amt3 : num 0 1000 1000 1200 10000 657 38000 0 432 0 ...
$ pay_amt4 : num 0 1000 1000 1100 9000 ...
$ pay_amt5 : num 0 0 1000 1069 689 ...
$ pay_amt6 : num 0 2000 5000 1000 679 ...
$ default_payment_next_month : logi TRUE TRUE FALSE FALSE FALSE FALSE ...Exploratory Data Analysis (EDA)
PlotUnivariateCategory <- function(df, column) {
ggplot2::ggplot(data=df, aes(x=.data[[column]], y=after_stat(count))) +
ggplot2::geom_bar(
stat="count"
) +
ggplot2::scale_x_discrete() +
ggplot2::scale_y_continuous(expand=c(0, 0), position="right")
}
AnalyzeUnivariate <- function(df, column) {
print(unique(df[[column]]))
if(typeof(df[[column]]) == "logical") {
print(summary(df[[column]]))
PlotUnivariateCategory(df, column)
}
}print(typeof(cardmembers_r$id))[1] "integer"print(typeof(cardmembers_r$limit_bal))[1] "double"print(typeof(cardmembers_r$marriage))[1] "NULL"AnalyzeUnivariate(cardmembers_r, "default_payment_next_month")[1] TRUE FALSE
Mode FALSE TRUE
logical 23364 6636 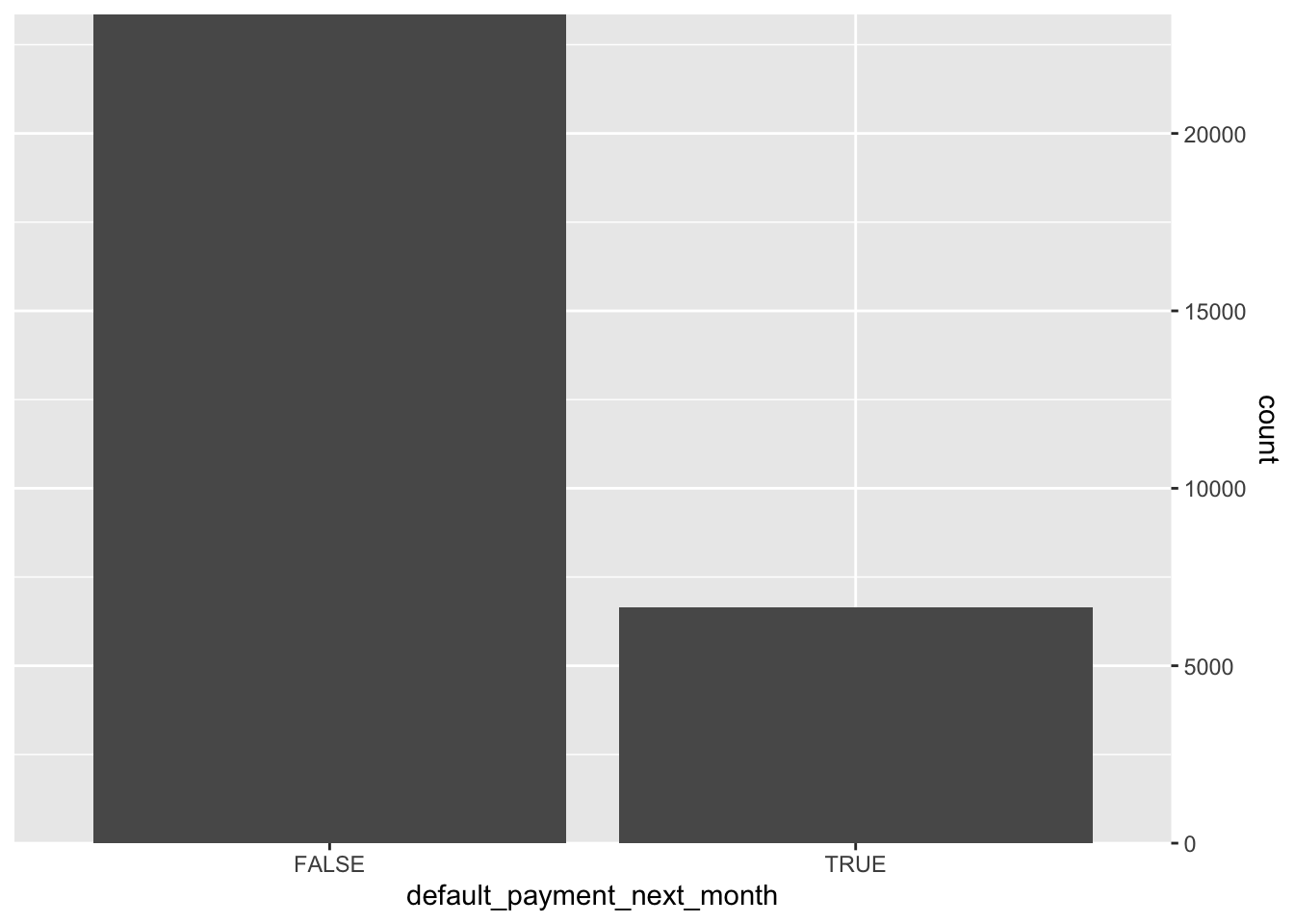
PlotBivariateCategory <- function(df, column_1, column_2="default_payment_next_month") {
ggplot2::ggplot(data=df, aes(x=df[[column_2]], y=(..count..), fill=df[[column_1]])) +
ggplot2::geom_bar(position="stack", stat="count") +
# ggplot2::scale_x_discrete(limits=c("Male", "Female", "Unknown", "Agender", "Gender Fluid")) +
ggplot2::scale_y_continuous(expand=c(0, 0), position="right")
# ggplot2::scale_fill_manual(values=c("Good"=palette_michaelmallari_r[19], "Neutral"=palette_michaelmallari_r[20], "Unknown"=palette_michaelmallari_r[21], "Bad"=palette_michaelmallari_r[2])) +
ggplot2::guides(fill=guide_legend(reverse=TRUE))
}
AnalyzeBivariate <- function(df, column_1, column_2="default_payment_next_month") {
PlotBivariateCategory(df, column_1)
}AnalyzeBivariate(cardmembers_r, "sex")<Guides[1] ggproto object>
fill : <GuideLegend>Data Preparation
Data Modeling
# model_rf_1_r <- randomForest::randomForest(formula=target~., data=train_clean_r, mtry=ncol(train_clean_r)-1, ntree=1000)
# summary(model_rf_1_r)#et_grid <- expand.grid(mtry=4:7, numRandomCuts=1:10)
#set.seed(1754)
#model_et_1_r <- caret::train(target ~ ., data=train_clean_r, method="extraTrees", trControl=cv_5, tuneGrid=et_grid, numThreads=8)
#summary(model_et_1_r)Model Evaluation
Appendix A: Environment, Language & Package Versions, and Coding Style
If you are interested in reproducing this work, here are the versions of R, Python, and Julia that I used (as well as the respective packages for each). Additionally, my coding style here is verbose, in order to trace back where functions/methods and variables are originating from, and make this a learning experience for everyone—including me.
cat(
R.version$version.string, "-", R.version$nickname,
"\nOS:", Sys.info()["sysname"], R.version$platform,
"\nCPU:", benchmarkme::get_cpu()$no_of_cores, "x", benchmarkme::get_cpu()$model_name
)R version 4.2.3 (2023-03-15) - Shortstop Beagle
OS: Darwin x86_64-apple-darwin17.0
CPU: 8 x Intel(R) Core(TM) i5-8259U CPU @ 2.30GHzrequire(devtools)
devtools::install_version("dplyr", version="1.1.4", repos="http://cran.us.r-project.org")
devtools::install_version("ggplot2", version="3.5.0", repos="http://cran.us.r-project.org")
devtools::install_version("caret", version="6.0.94", repos="http://cran.us.r-project.org")
devtools::install_version("randomForest", version="4.7-1.1", repos="http://cran.us.r-project.org")
devtools::install_version("extraTrees", version="1.0.5", repos="http://cran.us.r-project.org")
library(package=dplyr)
library(package=ggplot2)
library(package=caret)
library(package=randomForest)
library(package=extraTrees)import sys
import platform
import os
import cpuinfo
print(
"Python", sys.version,
"\nOS:", platform.system(), platform.platform(),
"\nCPU:", os.cpu_count(), "x", cpuinfo.get_cpu_info()["brand_raw"]
)Python 3.11.4 (v3.11.4:d2340ef257, Jun 6 2023, 19:15:51) [Clang 13.0.0 (clang-1300.0.29.30)]
OS: Darwin macOS-10.16-x86_64-i386-64bit
CPU: 8 x Intel(R) Core(TM) i5-8259U CPU @ 2.30GHz!pip install numpy==1.25.1
!pip install pandas==2.0.3
!pip install scipy==1.11.1
import numpy
import pandas
from scipy import statsusing InteractiveUtils
InteractiveUtils.versioninfo()Julia Version 1.9.2
Commit e4ee485e909 (2023-07-05 09:39 UTC)
Platform Info:
OS: macOS (x86_64-apple-darwin22.4.0)
CPU: 8 × Intel(R) Core(TM) i5-8259U CPU @ 2.30GHz
WORD_SIZE: 64
LIBM: libopenlibm
LLVM: libLLVM-14.0.6 (ORCJIT, skylake)
Threads: 1 on 8 virtual cores
Environment:
DYLD_FALLBACK_LIBRARY_PATH = /Library/Frameworks/R.framework/Resources/lib:/Library/Java/JavaVirtualMachines/jdk-21.jdk/Contents/Home/lib/server
DYLD_LIBRARY_PATH = /Library/Java/JavaVirtualMachines/jdk-21.jdk/Contents/Home/lib/serverusing Pkg
Pkg.add(name="HTTP", version="1.10.2")
Pkg.add(name="CSV", version="0.10.13")
Pkg.add(name="DataFrames", version="1.6.1")
Pkg.add(name="CategoricalArrays", version="0.10.8")
Pkg.add(name="StatsBase", version="0.34.2")
using HTTP
using CSV
using DataFrames
using CategoricalArrays
using StatsBaseFurther Readings
- James, G., Witten, D., Hastie, T., & Tibshirani, R. (2021). An Introduction to Statistical Learning: With Applications in R (2nd ed.). Springer. https://doi.org/10.1007/978-1-0716-1418-1
- Yeh, I. (2016, January 25). Default of Credit Card Clients. UCI Machine Learning Repository. https://doi.org/10.24432/C55S3H
Recent Thoughts